Discover how we helped businesses transform their operations with AI automation. Real results, measurable impact, and proven ROI across multiple industries.
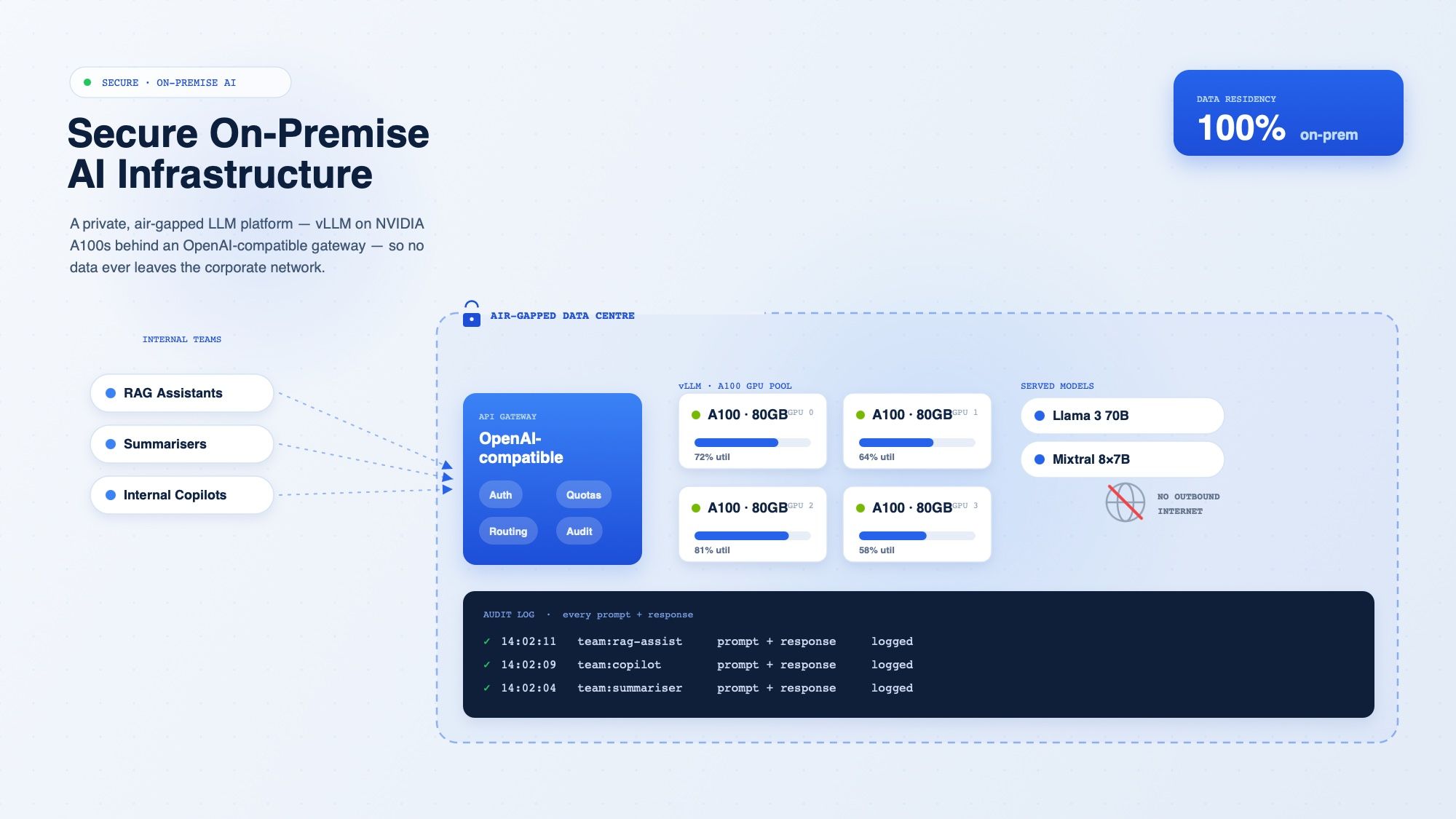
A private, air-gapped LLM infrastructure inside the customer data centre — vLLM serving on NVIDIA A100s — so every AI workload (RAG, summarisation, internal copilots) runs without sending data to public AI APIs.
The customer industrial data — equipment telemetry, technical documentation, internal procedures — could not legally or commercially be sent to public AI APIs.
At the same time, multiple internal teams wanted to ship RAG assistants, summarisers and copilots. Without a shared platform, every team would have rebuilt the same serving stack from scratch.
A shared LLM-serving platform on NVIDIA A100 GPUs running vLLM behind an OpenAI-compatible API gateway.
Internal teams consume it like any LLM provider, but every byte stays inside the corporate network. Quota, audit logging and model routing are handled at the gateway so teams do not reinvent infrastructure.
vLLM serves multiple open-weight models (Llama 3 70B, Mixtral) on a pool of A100 GPUs.
An OpenAI-compatible API gateway handles authentication, per-team quotas, model routing and audit logging.
Storage and observability run on the customer existing on-prem Kubernetes and Prometheus/Grafana stack. The whole environment is air-gapped with controlled artifact ingress for model and dependency updates.